

先日、「耳の話」なんかを書いたのでその辺りの話をもう少し書いてみます。
耳の奥、蝸牛は AGC (Auto Gain Control) 機能付きの高性能アクティブセンサーである、みたいな話だったのだけど、その有毛細胞によるフィルタバンクで周波数分析された音声信号はそのままパラレルに脳のニューラルネットに入力されるわけですが、これってそのまま「スペクトログラム」なんですよね。横軸が時間、縦軸は周波数でどの部分にエネルギーが存在しているかを表すグラフです。あの声紋分析なんかで使われる奴です。
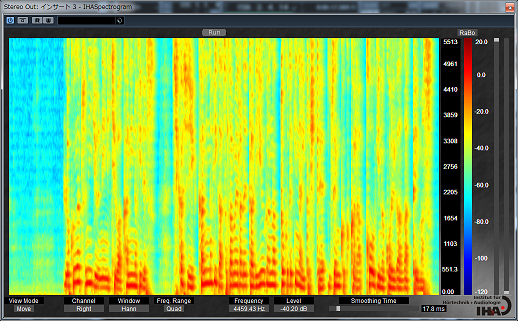
コンピュータによる音声認識でも同じように入力された音声はまず FFT とかで周波数分析しますが、問題はこのあとどう処理するかです。母音の判定をするためにフォルマントを抽出してみたりフォルマントの時間的な動きを抽出してみたり、音素を判定してみたり、HMM で辞書と比較してみたり、とこれまでに様々な職人芸的音声処理が試行錯誤されてきたのですが、徐々に改善はされるものの中々精度が良くならない、という時代がコンピュータの黎明期からずっと、50年近く続いていたわけです。この時代は多分認識の精度としては精々70%~80%くらいだったかと思います。フォルマントの動きを特徴量として抽出して隠れマルコフモデル(HMM)で判定するというのがこの時代の代表的なやり方でした。
そして音声認識というとあまり実用的じゃないなというのが実際の所の評価。アプリケーションを限定すれば使えるケースもあるかも知れない、という程度。認識を2択、3択等に限定すればそれなりに動くけど間違っても許してね、という感じ。
それが2000年代頃に登場したディープラーニングの応用でいきなり様相が変わります。DeepMind社のWaveNetとかですね。割とすぐにGoogleに買収されましたけど。今までより明らかに優れた認識精度! これは職人芸的な様々な判定手法じゃなく、とにかく抽出したフォルマントとかの特徴量をまとめてニューラルネットに放り込んで大量の学習データでぶん回せばなんとかなるんじゃないかという丸投げ方式ですが、これが今までの緻密にチューニングを繰り返してきたやり方をあっさりと上回る品質が出てしまったわけです。
そして更に10年ほど経った2010年代、再びショッキングな事実が明らかになります。
最終的な判定にニューラルネットを使うとしても、入力する前段階の処理としてこれまではフォルマントの動きやらを職人芸的手法で抽出していたのですが、もしかしてこれ、要らないんじゃね? と。そして周波数分析をした後のスペクトログラムをそのまんまニューラルネットにぶち込んでも学習さえちゃんとやれば動作するんじゃね? と。
そして案の定職人芸の敗北。周波数分析とニューラルネットだけを使って大量の学習データをぶん回す事で、より良い結果が出てしまいました。この構造は図らずも人間の耳から脳に周波数分析データをパラレルにぶっこんでる構造と同じ、職人芸的ロジックとかはどこにも入っていません。ある意味ずいぶんシンプルになってしまいました。ニューラルネットの中身というのは割とブラックボックスなのでミクロな視点で何がどうなってこういう結果が出るのかと言われると説明は難しい事になってしまいましたが、言葉を知らない赤ん坊が大量の言葉を聴いて覚えていくように人間がロジックをこねくり回すよりも自然現象として言葉をおぼえてしまう、みたいな事になっています。
シンギュラリティポイントの始まりみたいなものを感じますね。今後どうなるんでしょうね。

